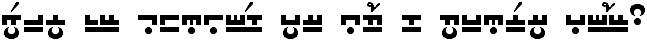
zubfəʃɛo
zubfəʃɛo
This script is a Phonological Cypher, being an easily written, phonetically consistent alphabet like others in that series. It differs from some others, in having broader phonetic groupings and less featural regularity, helping to make it quite simple and efficient in print. It was designed with English in mind, and offers a simple method for preserving the historically significant but irregular spellings of the original written language, while at the same time offering perfectly regular phonetic decipherment. The script and method might also be applied to other languages with similar “problems”, such as French, Gaelic or Tibetan. The name comes from the Sgai language, and means recognizing history.
Letters
There are four groupings, each with a shared set of shapes above the baseline, and then one of four underline shapes. The groups are for vowels (no tongue contact), fricatives & approximants (nearly tongue contact), plosives & nasals (full tongue contact), plus a fourth for extra letters and sounds as required (English has no real need of these). Diphthongs are written sharing a single under-shape.
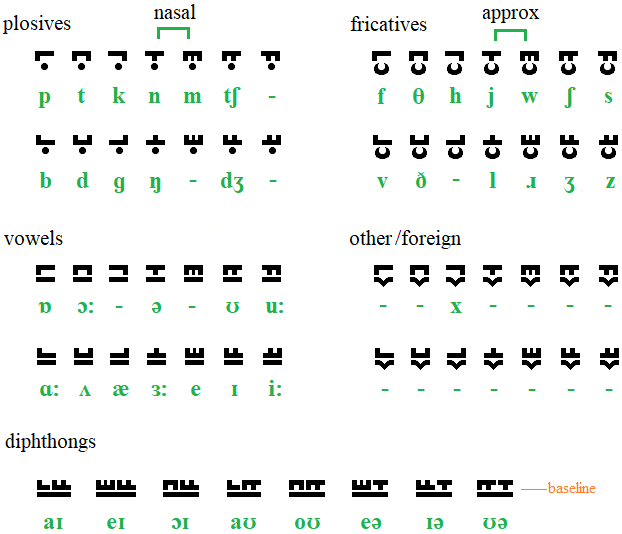
The above-line shapes indicate something of the articulatory region involved, and can be resolved to as small as 2×5 pixels. Because of the shallow profile of the main body of the script, it is easy to accommodate an extra region above for the use of modifying diacritics, or as they become here, etymological markers.
Etymology and disambiguation
It is well known that English spelling has many irregularities, with very few letters having a single sound, and with the majority of sounds each having up to a dozen possible spellings. This is unlike a phonetically consistent alphabet (there do exist many languages using such a thing) – where phonemes match graphemes in all words – and while it seems like a good idea to re-spell English in a phonetical manner, such a system hides the complex, quaint, interesting, gossip-worthy appearance of the original written language. The odd spellings, of course, show us where words evolved from, and give us glimpses into the history of words and the subtle meanings they accrued over time.
In an attempt to satisfy both the ideal of phonetic consistency and the need for appreciating etymological elements, it is suggested here that a marker can be used upon a (phonetic) glyph to indicate or suggest which original grapheme is being encoded. My first idea was to refer to an authoritative list for standard English which included all variations ordered by frequency of use, then simply number the variations & write the number (in stylized Arabic or Roman numerals) above the phonetic glyph.
But with up to a dozen variations – see for example the 44 English phonemes with spelling listed at Dyslexia-Reading-Well.com – it would quickly become tedious to encode dogmatically. Indeed we are not intending here to provide lessons in spelling, but to help clarify words that might seem unfamilar when presented in a purely phonetic format, or to disambiguate in a meaningful way words that might sound similar (homophones). An extra benefit of marking the variations, whether in cursory or absolute fashion, is to remind those of us who are curious, of the chronolinguistic development of words from Old English, Latin, Greek, French etc through writing. Indeed, another option – not explored here – would be to encode the language of origin directly, so we could see clearly the reason for the variation.
Minimal system
As a compromise, I decided to use no more than three number-marks (plus “no mark” for the commonest grapheme) with the numbers increasing as the variations become less common. Number-mark 3 includes all variations beyond the second. Note that this is looking to the frequency of use of the grapheme, not the word containing it. The criteria are somewhat relaxed, so that for example graphemes consisting of a doubled letter are treated as a single one, and silent consonants may be unencoded, or merged into the nearby grapheme.
| phoneme | grapheme variations | phoneme | grapheme variations | ||||
| IPA | 0 | 1 | 2 | IPA | 0 | 1 | 2 |
| b | b | æ | a | ai | |||
| d | d | eɪ | a | ai | ay | ||
| f | f | ph | gh | e | e | ea | ai |
| g | g | gu | gh | i: | e | ea | -y |
| h | h | ɪ | i | y | ie | ||
| dʒ | g | j | dg | aɪ | i | ie | igh |
| k | c | k | ck | ɒ | o | au | aw |
| l | l | oʊ | o | oa | ow | ||
| m | m | -mb | -mn | ʊ | oo | u | ou |
| n | n | kn | gn | ʌ | u | o | oo |
| p | p | u: | u | ew | o | ||
| ɹ | r | wr | rh | ɔɪ | oi | oy | uoy |
| s | s | c | sc | aʊ | ou | ow | ough |
| t | t | -ed | th | ə | a | i | -er |
| v | v | f | ph | eə(ɹ) | air | -are | -ere |
| w | w | u | wh | ɑ: | ar | a | |
| z | s | z | x | ɜ(ɹ) | ir | er | ur |
| ʒ | si | s | g | ɔ: | or | aw | oar |
| tʃ | ch | tch | t | ɪə(ɹ) | -ear | -eer | -ier |
| ʃ | ti | sh | ci | ʊə(ɹ) | -ure | -our | |
| ŋ | ng | n | -ngue | j | i | y | j |
| ð | th | ju: | u | ew | ue | ||
| θ | th | ||||||
It is possible, of course, to use the script without the variation markers at all. An intermediate situation has us using the markers only for clarification purposes. Full use would present the reader with an interesting extra dimension upon the rendering of the sounds, a quasi-historical association. It also depends whether a word needs to be recognized in isolation, or just in a given context.

Strict homonyms
Words which in the original English have the same sound and same spelling (homophones + homographs) give no graphemic clues to differentiation, unlike typical homophones mentioned above. In many cases there has been a parallel shift in meaning, but in others there was simply a coincidental evolution. Still, we cannot encode the graphemes for disambiguation in the same way as described above. In this script we have a special suffix to indicate relative or absolute rarity of the attached word. If there are more than two variations in the same article, a number-mark may be added (it is conceivable that a word like <lie> may be used in three different ways in a story about murder on a golf course, for example). Or, in the common case where one is a noun & the other a verb the number-mark 2 can be used with the verb, since it looks like a v.
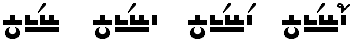
Punctuation
There are a number of punctuation marks fitting with the script’s style.
Example
A fully encoded transliteration of the beginning of Shakespeare’s Sonnet XVIII.
Shall I compare thee to a summer’s day?