The Mysterious Voynich Manuscript
Observations
Ian James
© February 2009
|| Quick Intro
| Content & Reason for Being
| Word Structure
| Word Frequency
| Notes on Morphology ||
Quick IntroFor background on history, layout & basic insights into the document, and further links, see www.voynich.nu. Other info on Wikipedia etc. In summary, the Voynich MS is a document of unknown origin, written in an unknown script and unknown language, by almost all accounts still completely undeciphered. Dated to roughly the Renaissance period, its earliest known mention is in records from the Bohemian court in Prague of the 16th century. There are 1,900 paragraphs and 37,000 words across 228 pages, with illustrations of plants, stars, and quasi-biological figures.
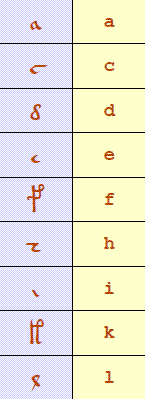
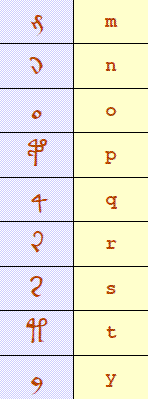
The EVA systemIn this system, each char (symbol) has been mapped to a Latin char, based on similarity of shape and with a satisfactory mix of consonants and vowels, to enable the original chars to be easily recognized and the words to appear vaguely readable. The ones appearing 100 times or more (out of the total 180,000 so 99.94% appearance) are:
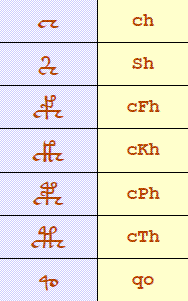
In addition, EVA has editorial symbols including:
There are many difficult-to-read chars, and there may actually be more or less foundational chars in the set, and thus a lingering confusion over how best to identify and define them. For example, in the small text sample above (originals at Yale University) it can be seen that q can look like y Content and Reason for BeingWhat we knowIt is important to note that until even just a single word has been translated, all theories, arguments, and expert contribution remain empty conjecture & noise. The common complaints over lack of information and imperfections in the original are also somewhat distracting. The manuscript is the work of a human communicator working within a mental framework all humans share. Even if only 50% of the text was available, or 5%, or one page, the amount of indisputable orthographic evidence is still enough that we should find some meaning. Otherwise it shows up as a weakness in our understanding of human communication. Back to work, everyone. Some observers have suggested the document contains:
Unlikely gibberish nor a hoaxThe organization of the chars is elaborate and consistent, resembling natural language. It passes various statistical linguistic tests, and is non-random, curiously varied, intentionally structured. It runs smoothly off the pen. As it stands, however, a straight reading of the chars as an alphabetic system is unusual and baffling. It has proved to be an enormous challenge over the centuries. But this does not imply the author designed it as such, or as a joke, or to feign knowledge of some strange magical tongue. It certainly required a great deal of effort and time to produce, and for a document with only very dull or very bizarre illustrations and no clear show of typically “magical” content, casual readers would hardly be bothered with it. Except for the writing system itself. Code-breakers disappointedMany have attempted decipherment of the text by applying techniques of cryptography and mathematical analysis. The lack of success may be due not to the script system being intentionally obfuscated, but conversely, to it being meaningful of itself. In the same way natural language cannot be coldly decoded, the text may be expressing phonemes or words or ideas directly, somehow. There is yet no known system of generic translation from one language-set (or idea-set) to another. There is also some suggestion the text includes contributions from more than one hand. This would imply a mutual understanding and agreement on how to use the language, and a straightforward means of teaching or transferring it. Even if the author is one person, the variations in handwriting would suggest different periods, and a long span of work, and a straightforward personal method which defied change, evolution, and tedium. The slight differences found by some statistical analyses may come either from different authors preferring slightly different grammatical paradigms (eg. passive rather than active verb-tense), or one author developing new preferences—perhaps a swifter, terser expression—over time, or simply from wording dependent on different topics. The final bundling of folios does not reflect the original timeline, for either subject exploration or style or additions. Many patterns which emerge in the search for phonemes or syllables suggest either too great a set, or results which do resemble gibberish. It seems a deeper structure is involved, or the units refer to something other than spoken sounds, as in an artificial language. Or the language is natural, but particularly exotic. Why record a foreign language this way?From our present knowledge of world languages and script systems, the language of the (single-instance) Voynich document is unique. If someone had presented it as an example from a strange country of their writing, we would certainly know of other instances by now. Or if a monk or scholar was visiting a strange country and wanted to study and record local knowledge (as has happened), such a form might be invented for the purpose, especially if the foreign language had no script of its own. Modern examples of this include Cree and Hmong. But the writer would surely seek to make it more accessible to the readers back home, not less so. Perhaps the intended key to the system became lost, and the work sadly (for the author) unreadable to others. But even then, surely something of the local culture would have appeared in the illustrations, perhaps even in the letter-forms, some token of his journey & new environment. Indeed it seems to resist local input, from the writing itself down to the depiction of non-mundane, even unreal activities. Another option is that the author himself1 is foreign, and is recording his own (very different) language using an invented script based loosely in the Roman/classical tradition of his new home. Script invention is not uncommon in private communications2. An invented languageThe script is reminiscent of those used in manuscripts written in Europe, but without any correspondences in the detail. One important observation is that while the author did not produce finely drafted illustrations, and appears from those to lack sophisticated (scientific) knowledge of botany, biology and astronomy, he does seem to display a profound interest in language and script design. To create a sophisticated encoding system and be able to express himself in elegant and consistent fashion over the length (and timespan) of the document holds the greatest fascination. And thus also relevance to the Language for the World project. But not only does the invention of a new script warrant admiration, it seems by virtue of the difficulties in decipherment that the language it expresses may not be a natural language of phonemes or syllables, but a synthetic language. There have been several significant attempts at creating an artificial or universal language expressing ideas rather than sounds3 and this might rank as an early example. Typically, “words” are used as descriptions or pointers of location within a comprehensive taxonomy of concepts. Such a system, however, would be difficult to use in everyday fashion, and would certainly revert to shortcuts or arbitrary assignments. And it would make translation (or review at a later date) near impossible without a key. Another option is that the synthesis does not involve taxonomic lookup, but grammatical or morphological construction. One might, for example, look at Latin, Greek or Arabic (with historically well-analyzed grammars) and invent a simplified version of such grammars. Or perhaps apply their paradigms to one’s own (very different) native language, to create a personal hybrid. This would be much easier to maintain and use. A further option is a combination of these approaches, in the manner of Chinese or Sumerian: semantic units with grammatical modifiers. An important possible clue to this option is the way many words appear together which are spelt the same but for one or two chars. This will be seen whenever the (written) vocabulary is based on the same semantic root. For example, a sentence in Chinese about metalwork will have an inordinate number of characters containing the radical (sub-character) metal. In any case, it would have had to make sense to the author; and perhaps as a welcome side effect—enhancing privacy—it would make little sense to casual observers. And all these things highlight the author’s interest in language/linguistics and the expression of uncommon knowledge. Secrets worth unlocking?Even though the text is certainly not a jumble of chars with slim connection to human language, it remains to be seen whether the content is something we might actually understand, or want to read. It may be the ravings of an alchemist high on quicksilver fumes, or a maverick thinker locked in a world of his own. One possible clue to its having some value to seekers of esoteric knowledge is the fact that some pages are missing. Some have been cut out, some may have fallen out. If these contained keys to the translation and/or epitomes of the content, perhaps a “secret society” is keeping the useful knowledge to themselves. And certainly, alchemists/magicians/thinkers of the calibre of Athanius Kircher and John Dee may have looked over the manuscript; they and/or their many alchemical peers in Renaissance Europe—who were closer to the source—may have had a very good idea about the value of the document, and recognized not only the gems it contained, but also various shared methods for decoding it. Mystic philosophyIf the contents are rather the personal musings of a radical thinker, or a collection of exotic ideas gathered from foreign sources, there is still the possibility it holds great interest philosophically. For example, and judging merely by the naive and abstract illustrations, the author is likely not expressing details of natural phenomena, but concepts based on them. At casual first glance, and assuming deep philosophical interest either intrinsic to the material itself or held by an ever-hopeful modern observer, the following sets of illustrations may be supplementing certain esoteric topics:
But even if the content is interesting & relevant to us today, it may still remain cryptic for us by virtue of the use of abbreviations and jargon and archaic references, even after the text has been translated into a linguistically feasible form – just as alchemical texts remain for non-alchemists. In any case, it remains a fascinating case of linguistic invention, with enough curiosity value to invite at least some interpretation. Word StructureFrequencies of appearanceIn a simple preliminary breakdown of char frequency, getting ready for “code-breaking” efforts, we find (ignoring occurrences of less than 100):
Orthographic familiesIt is interesting to look at the chars themselves, and how they may have come to be chosen and used. The simplest shapes are i e o, and several chars can be seen as relations of them. These can also be arranged by direction of initial pen-stroke and addition of tails etc: Some chars can fit more than one spot in the table, and those options are dependent on movement of the pen. It is difficult to know whether a char is conceived the same way it is constructed.
Some key points:
Calligraphic additionsSome observers have suggested that some of the base (18 common) chars are no more than calligraphic variations of each other, and hold no separate value in the system. It is certainly possible that some of the other, rarer symbols have additions with only decorative value. But it is unlikely that the person who has carefully constructed an entire writing system—and probably its language as well—would then wantonly abandon the complex & orderly invention, without adding meaning. Orthographic referencesThe similarity of many chars to Latin chars (and hence the choices that came to be made for the EVA system) would have been apparent also to the author, if he was based in the European Renaissance or Medieval writing tradition. This may have aided his own translation into the system; and we may have some chance of translating back if we can imagine his thought process in reverse. Probably the most inviting reference is seen in the multiple use of i which reminds us of the Roman numeral system. Indeed the existence of multiples of i and e and sometimes o strongly suggests counting or labeling with indices. Counts or index-numbers may have been included:
Another small clue may lie in the use of the o and e shapes as found in musical notation of the Medieval period:
This might then leave i to represent (quite naturally) a level of singletons. It is important to note that i and e are the only chars to appear (overwhelmingly) in neither initial nor final position. Another point is that the set of chars k t p f might play a role semantically flagging, raising or accenting, by virtue of their height above the median channel. In a similar way, final-position chars have tails: a common feature of writing where a flourish is the physical rounding-off of a thought. It has been suggested the gaps reminiscent of word breaks actually do not delimit words, but are arbitrary (to intentionally confuse), or based on space belonging to what looks like a final char (in the manner of Arabic unlinked letters /d/, /r/, /w/). Almost universally, gaps delimit either words or phrases, but could feasibly delimit syllables as well. The VMS may either be very efficient and abstracted, forming compact phrasal units, or full of redundancy in simpler units like phonemes and syllables. If the gaps were arbitrary or atypical, it would imply the author had a clear method of discerning the proper caesurae for himself, likely quite obvious to him from the series of chars and its overriding structure. Word FrequencyIt can appear that the Voynich MS has too much variety and too little repetition, to be a viable text. But look at the top 7 most frequent words, and compare with English (Brown Corpus) the percent frequency:
Notes on MorphologyGeneric wordsEach word of the Voynich MS had to be written down following some system, ideally avoiding tedious lookup and encryption, and facilitating review by the author. It seems unlikely then that its words are units matching some idea-horde one-to-one. More useful (in terms of language use and re-use) is a system which incorporates a grammar and/or gives words additional markers to extend more general roots semantically. The tendency-of-position table above gives some guidelines as to the generic word form, and perhaps a first approximation of: But not surprisingly, there emerge many rules about which chars may precede or follow which other chars. See the components table for a full summary of commonest forms/pathways. Among the clearest forms are suffixes surrounding i and following a: where . represents a word break and + possible further pathways. It can be seen the chars are all written with an I-family stroke. If words have more than one part, each part within the word would have a beginning and ending, or some divider or pivot between the parts. It seems for example that only I-chars can follow a which may in turn be a head for components like this. Minimum wordsThe only 1 and 2 char words appearing more than 10 times (the most frequent word overall is daiin appearing 892 times, and 66% of all words appear only once) are: s y r o l d m kThese would typically be either grammatical particles which commonly resist semantic breakdown, such as and or may or even though etc, or the smallest possible semantic constructions, showing us for example a bare root or null affix or small root + small affix. See the shortest words table for a fairly complete list of 2 and 3 char words. [--work in progress--]
Notes
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


All material on this page © Ian James, unless otherwise stated.
Last modified Feb.22,2009